什么是CAP定理
什么是CAP定理?
CAP定理告诉我们,一个分布式系统不可能同时满足一致性(C:Consistency),可用性(A: Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中的2个。
2000年的时候,Eric Brewer教授提出了CAP猜想,2年后,被Seth Gilbert和Nancy Lynch 从理论上证明了猜想的可能性,从此,CAP理论正式在学术上成为了分布式计算领域的公认定理。并深深的影响了分布式计算的发展。
C:一致性
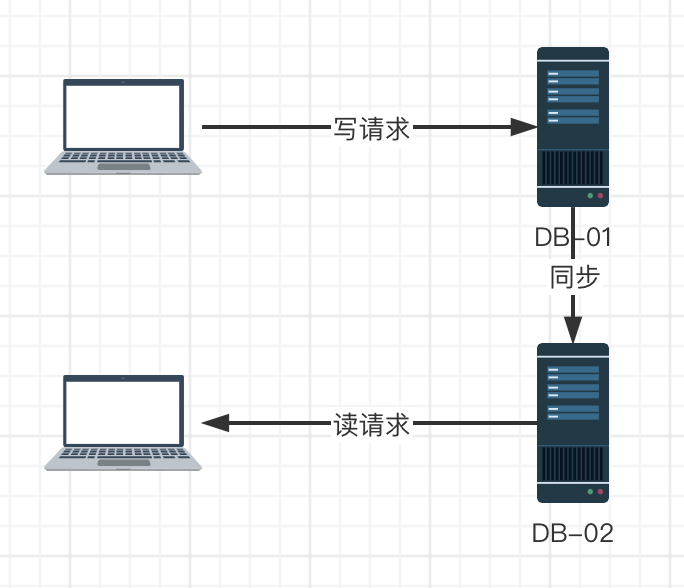
在分布式存储系统中,如果在一个节点上成功进行了写操作,在另外一个节点上可以读到上一个节点写操作之后的结果,我们就认为系统具有一致性。
all nodes see the same data at the same time.
A:可用性
任何客户端的请求都可以被成功的响应。
怎么来理解呢?这里先讲一个笑话:
A:我心算特别快。
B:82342342乘以234234等于多少?
A:等于345333。
B:你确定算的对吗?
A:对不对你先别管,你就说算算的快不快吧~
回到正题,可用性看中的是系统的正常响应,系统并不会因为部分服务宕机而不可用。
举个例子:假设数据库服务宕机,(当时可能已经有写操作成功了,数据可能被同步到了其他节点,也可能没有同步到其他节点),那么其他客户端的访问就会被转发到正常的数据库服务器上,这样保证了数据库服务的可用性。
要注意的是,这里保证的是可用性,并不一定保证准确性(或者说一致性),有可能DB-01上的数据版本已经变成了V2,但是DB-02上的数据还是V1.
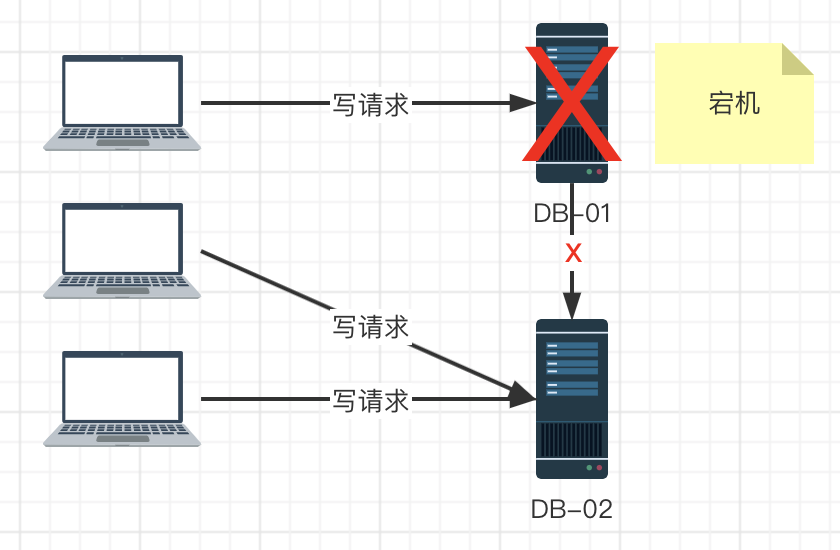
这种场景下,如果一定要保证一致性,会出现什么结果呢?
如果一定要保证一致性,那么整个系统必须停止对外提供服务,等待DB-01恢复并且数据同步完成之后,整个系统才能继续对外提供服务。
简单来讲:
要保证一致性,就要牺牲可用性;要保证可用性,就要牺牲一致性。
P:分区容错性(隔离容错性)
不同的人对于P的翻译有所不同,有的叫分区容错性,有的叫隔离容错性,不过他们所描述的场景是一样的:在分布式系统中,存在一部分节点因为网络问题,被分成(或隔离)成了不同的组。
如下图所示:
原本DB-01至DB-05是一个集群,但是由于DB-01和DB-02所在机柜的网络设备异常,导致和DB-03、DB-04、DB-05三个节点的机柜网络不通了,这就造成了所谓的分区。
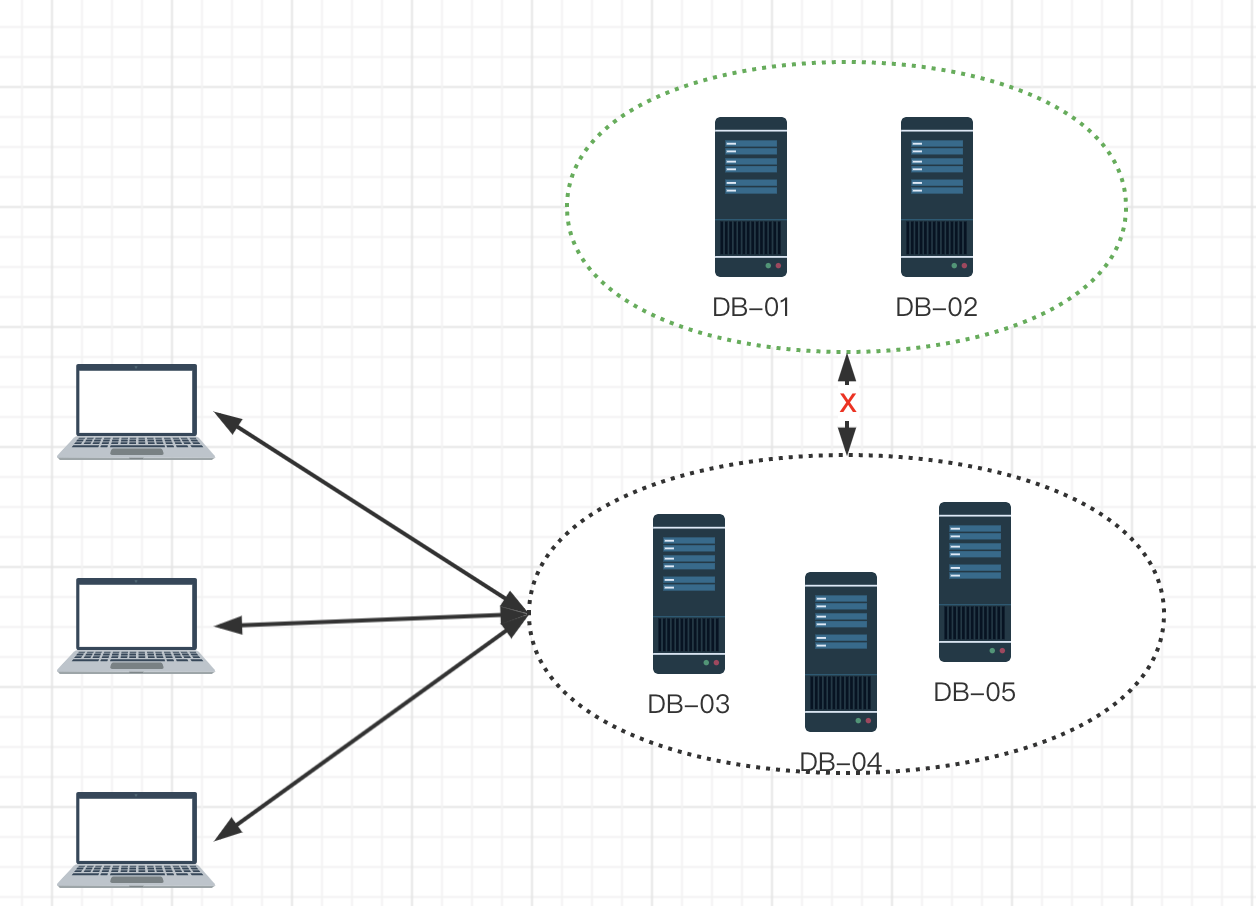
在分布式系统中,网络是不可靠的,由于网络设备故障或其他原因导致的网络不通等原因是不可避免的,一旦出现了网络故障,造成了节点之间的隔离,整个系统还应该对外保持一定的服务能力。
为什么分布式系统只能同时满足两项?
CAP是一个定理,是经过前人论证过的一个为真的结论,他告诉我们分布式系统中,CAP只能满足其二。
我们可能无法知晓详细的论证细节,但是也可以大致推断一下:
P是一个必选项
为什么这样说呢?因为抛开了P,再去讨论C和A,没有任何意义。造成一致性(C)和可用性(A)问题的根本原因是分布式架构,分布式架构必然存在分区(隔离)容错性的问题,所以不能抛开P去讨论C和A,如果没有P,系统只是一个单体应用,也就自然不存在C和A的问题。
C和A能否共存(同时满足CAP)
试想一下上文提到的可用性的例子:在保证可用性的前提下,如果还要保证数据一致性,那么必须等待宕机的数据库服务恢复,在此期间所有的外部请求都将被阻塞。
这样显然是不符合我们实际情况的。
CP和AP
既然CAP不能同时共存,P又是必选项,所以我们在实际使用中,会结合实际的业务需求选择CP或者AP。
CP:比如zookeeper
AP:比如Eureka
为什么读了那么多CAP的文章却感觉似懂非懂?
CAP是一个学术界的理论(宏观方向),我们是站在实操的角度去看待这个问题的(微观细节),因此在阅读这些文章的时候,千万不要钻牛角尖。
比如一致性问题,我们真的可以保证A节点写完了数据,同一时间在B节点上就可以读到数据吗?真的就没有一点点延迟吗?实际情况肯定不是这样的,我们会考虑:强一致性、弱一致性、最终一致性。如果套在理论里,岂不是莫名其妙的。




